各位大师拜托了! 我想检索WTO文献中的like products, similar products 和identical products 的出现频率,用wordsmith 4.0试了一下没检索出来!请各位指点!多谢!
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
想检索like products, similar products 和identical products的频率?
- 主题发起人 ssy12131002
- 时间
李亮1975重庆
语料库快乐军政委
TXT全能转码器李亮版.rar
【第一步,判断你的文件类型】你随便打开一个你的语料库文件,也就是“双击一下”,看看是不是“记事本”就弹出来打开了当前的这个文件,如果是“记事本”弹出来了,就说明你的语料库文件是txt文件,如果是Internet Explorer或360安全浏览器或Firefox或Chrome或"QQ浏览器"出来了,就说明你的语料库文件是“.htm”或“.html”文件。如果是Microsoft Word运行起来了,就说明你是doc或docx或rtf的文件类型。
总之,如果你不是txt文件类型,你就需要进行其他文件类型转化为txt的操作,然后再走【第二步】。
如果你是htm或html文件的话,就应该用下面的工具来进行批量转换
http://www.nirsoft.net/utils/htmlastext.html
如果你是doc文件的话,就应该用下面的工具进行批量转换
http://www.skycn.com/soft/32308.html
http://www.crsky.com/soft/22633.html
http://www.duote.com/soft/25702.html
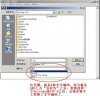
【第二步,判断你的文字编码】如果你的语料库文件都是txt,或者都已经被其他文件转换工具变为了txt文件,那么,你就需要双击其中一个".txt"文件,这时,“记事本”弹出来了,你点菜单上的“文件”的“另存为”,就弹出一个对话框,看下面部分的“编码”就是文字编码了,这下拉菜单有4个选项,而当前的被选中的状态就是“你的当前文件的文字编码”,由此你就知道如何判断自己的语料文件的文字编码了,如果你的语料库文件的来源很多,就很有可能是这个txt文件是ANSI,而另外一个是Unicode,而再另外一个却是UTF-8,而还有一个是Unicode big endian,这4种可能性就是全部的”文字编码“。
所以,如果你需要批量判断你的大量的txt文件的文字编码到底是哪些?你可以使用我做的小工具”文字编码批量判断器李亮版“
http://ishare.iask.sina.com.cn/f/24746191.html
批量判断之后,就可以使用我开发的小工具”txt全能转码器李亮版“
http://ishare.iask.sina.com.cn/f/24743261.html
下载它,解压它,把它直接放到你需要从其他的3种文字编码进行转换的语料文件所在的文件夹,双击就运行起来了,然后在弹出的对话框选择你要转换为Unicode或其他编码。注意,这个软件只转换当前文件夹的txt文件哟,而不转换”子文件夹“的txt文件哟。什么叫”子文件夹“呢,就是你的一个文件夹里面的另一个或另一些文件夹,它们被包含在”父文件夹“中,所以叫做”子文件夹“。你要继续对子文件夹的txt文件进行处理的话,需要把我的小工具拷贝到它们里面去。
附件中的图片是屏幕截图,展示了如何操作和菜单的具体位置……
【第一步,判断你的文件类型】你随便打开一个你的语料库文件,也就是“双击一下”,看看是不是“记事本”就弹出来打开了当前的这个文件,如果是“记事本”弹出来了,就说明你的语料库文件是txt文件,如果是Internet Explorer或360安全浏览器或Firefox或Chrome或"QQ浏览器"出来了,就说明你的语料库文件是“.htm”或“.html”文件。如果是Microsoft Word运行起来了,就说明你是doc或docx或rtf的文件类型。
总之,如果你不是txt文件类型,你就需要进行其他文件类型转化为txt的操作,然后再走【第二步】。
如果你是htm或html文件的话,就应该用下面的工具来进行批量转换
http://www.nirsoft.net/utils/htmlastext.html
如果你是doc文件的话,就应该用下面的工具进行批量转换
http://www.skycn.com/soft/32308.html
http://www.crsky.com/soft/22633.html
http://www.duote.com/soft/25702.html
【第二步,判断你的文字编码】如果你的语料库文件都是txt,或者都已经被其他文件转换工具变为了txt文件,那么,你就需要双击其中一个".txt"文件,这时,“记事本”弹出来了,你点菜单上的“文件”的“另存为”,就弹出一个对话框,看下面部分的“编码”就是文字编码了,这下拉菜单有4个选项,而当前的被选中的状态就是“你的当前文件的文字编码”,由此你就知道如何判断自己的语料文件的文字编码了,如果你的语料库文件的来源很多,就很有可能是这个txt文件是ANSI,而另外一个是Unicode,而再另外一个却是UTF-8,而还有一个是Unicode big endian,这4种可能性就是全部的”文字编码“。
所以,如果你需要批量判断你的大量的txt文件的文字编码到底是哪些?你可以使用我做的小工具”文字编码批量判断器李亮版“
http://ishare.iask.sina.com.cn/f/24746191.html
批量判断之后,就可以使用我开发的小工具”txt全能转码器李亮版“
http://ishare.iask.sina.com.cn/f/24743261.html
下载它,解压它,把它直接放到你需要从其他的3种文字编码进行转换的语料文件所在的文件夹,双击就运行起来了,然后在弹出的对话框选择你要转换为Unicode或其他编码。注意,这个软件只转换当前文件夹的txt文件哟,而不转换”子文件夹“的txt文件哟。什么叫”子文件夹“呢,就是你的一个文件夹里面的另一个或另一些文件夹,它们被包含在”父文件夹“中,所以叫做”子文件夹“。你要继续对子文件夹的txt文件进行处理的话,需要把我的小工具拷贝到它们里面去。
附件中的图片是屏幕截图,展示了如何操作和菜单的具体位置……