xusun575
高级会员
回复: paraconc使用
I'll wait and see.
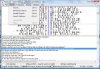
Your problem is caused by incorrect encoding. You will need to save the Chinese file as UTF8, and check the box UTF8 when you load the corpus into ParaConc.
As you have marked up the segments, you can also specify the tag <seg>.
I'll wait and see.