You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
求助自建语料库步骤
- 主题发起人 zxyzh09
- 时间
李亮1975重庆
语料库快乐军政委
《语料库工程的15个常见环节:切勿轻视》
《语料库工程的15个常见环节:切勿轻视》
http://www.corpus4u.org/forum/showthread.php?t=8246
《语料库标注的“自助14步”》
http://www.corpus4u.org/forum/showpost.php?p=45791&postcount=5
我开发的一些“李亮版语料工具”在“新浪爱问”的专门页面,欢迎浏览下载……
http://iask.sina.com.cn/u/1411332842/ish
《语料库工程的15个常见环节:切勿轻视》
http://www.corpus4u.org/forum/showthread.php?t=8246
《语料库标注的“自助14步”》
http://www.corpus4u.org/forum/showpost.php?p=45791&postcount=5
我开发的一些“李亮版语料工具”在“新浪爱问”的专门页面,欢迎浏览下载……
http://iask.sina.com.cn/u/1411332842/ish
回复: 《语料库工程的15个常见环节:切勿轻视》
太感谢李老师了!!!很感到,这是我第一次在internet上发主题,并且得到回答。《语料库工程的15个常见环节:切勿轻视》
http://www.corpus4u.org/forum/showthread.php?t=8246
《语料库标注的“自助14步”》
http://www.corpus4u.org/forum/showpost.php?p=45791&postcount=5
我开发的一些“李亮版语料工具”在“新浪爱问”的专门页面,欢迎浏览下载……
http://iask.sina.com.cn/u/1411332842/ish
李亮1975重庆
语料库快乐军政委
我的语料库技能视频与“语料搜集的爬虫综述”
http://www.youku.com/playlist_show/id_5427313.html
计算词典学的最高理想是“词典编纂的自动化”,可以分为“理论探索层面”,“产品评论层面”,“操作实践层面”,“编程开发层面”这四大层面。本教程是针对“操作实践层面”,是面向完全没有学习过任何计算机普及型的流行教程的词典学学生和词典编纂人员。所有视频不分观看的先后顺序,适合IT零基础的师生。半小时到一个多小时,就能斩获别处都学不到的技能,往往超越别人编程才能做到的“任务”。
http://www.corpus4u.org/forum/showthread.php?t=8269
原创《语料搜集:桌面级的网页抓取技术与工具》,个人也能轻松建立起“数亿词甚至数百亿词或数千亿词的语料库”……
http://www.youku.com/playlist_show/id_5427313.html
计算词典学的最高理想是“词典编纂的自动化”,可以分为“理论探索层面”,“产品评论层面”,“操作实践层面”,“编程开发层面”这四大层面。本教程是针对“操作实践层面”,是面向完全没有学习过任何计算机普及型的流行教程的词典学学生和词典编纂人员。所有视频不分观看的先后顺序,适合IT零基础的师生。半小时到一个多小时,就能斩获别处都学不到的技能,往往超越别人编程才能做到的“任务”。
http://www.corpus4u.org/forum/showthread.php?t=8269
原创《语料搜集:桌面级的网页抓取技术与工具》,个人也能轻松建立起“数亿词甚至数百亿词或数千亿词的语料库”……
回复: 我的语料库技能视频与“语料搜集的爬虫综述”
还有你有个关于语料库建立的在线视频链接,在另一个论坛里,貌似无效了。不知还有否其他可观看的视频链接呢?
李老师,你还在线上吗?还有LOCNESS语料库可以分享给我吗?看你发过的贴,没有LOCNESS语料库的语料库了。http://www.youku.com/playlist_show/id_5427313.html
计算词典学的最高理想是“词典编纂的自动化”,可以分为“理论探索层面”,“产品评论层面”,“操作实践层面”,“编程开发层面”这四大层面。本教程是针对“操作实践层面”,是面向完全没有学习过任何计算机普及型的流行教程的词典学学生和词典编纂人员。所有视频不分观看的先后顺序,适合IT零基础的师生。半小时到一个多小时,就能斩获别处都学不到的技能,往往超越别人编程才能做到的“任务”。
http://www.corpus4u.org/forum/showthread.php?t=8269
原创《语料搜集:桌面级的网页抓取技术与工具》,个人也能轻松建立起“数亿词甚至数百亿词或数千亿词的语料库”……
还有你有个关于语料库建立的在线视频链接,在另一个论坛里,貌似无效了。不知还有否其他可观看的视频链接呢?
李亮1975重庆
语料库快乐军政委
回复: 求助自建语料库步骤
LOCNESS在论坛的“悄悄话”中给你提供链接了。
我个人制作的语料库视频和我推荐的语料库视频都在
http://www.youku.com/playlist_show/id_5427313.html
LOCNESS在论坛的“悄悄话”中给你提供链接了。
我个人制作的语料库视频和我推荐的语料库视频都在
http://www.youku.com/playlist_show/id_5427313.html
李亮1975重庆
语料库快乐军政委
语料检索工具的功能的最凝练概括
http://www.lexically.net/downloads/version6/HTML/index.html
语料库检索工具的主要功能都差不多,一般人需要的功能就是20个左右而已,WordSmith有一些建库的辅助功能,但是一般人往往没有时间精力和技术知识背景来建库的,例如XML的知识基础。所以,AntConc就是优秀而免费而够用的工具了;WordSmith只是名气大而已,过去的10年里,它和AntConc都开发进展非常迟缓,三五年才更新一次,也更新幅度很小,而世界上的语料工具开发者急缺,所以,外语界只能受制于这样的“有限工具”了。
http://wenku.baidu.com/view/195a3704cc175527072208a3.html
http://www.lexically.net/wordsmith/step_by_step_English6/index.html
WordSmith的众多功能就是两大类:建库功能,用库功能。从宏观到微观可以简明概括如下……
【文件】或【库】统计,对比,拆合,查看,移动,核查,抓取,更名
【词】或【词块】统计,对比,检索,替换
【标注】统计,忽略,剥离
【字符】转换,清理
【最宏观的层次】也就是在对你建库或构成库的众多文件进行统计呀,对比呀,拆分或合并呀,查看阅读呀,移动呀或更名呀,核查完整性呀,抓取大量网页来建库呀。
【最常用的层次】是“词与词块”这个层面的“那些事儿”,量的多角度对比呀,位置的统计或快速确定呀,替换一些字词呀。
【次常用的层次】是“标注”的“纵横使用与计算”;
【最底层或最微观的平面】是字符层面的编码转换了。
AntConc是免费,仅仅缺乏“文件与库”的这个最宏观层面的功能,更微观的更常用的都有了。其实,建库功能也能找其他软件来实现的。
http://www.lexically.net/downloads/version6/HTML/index.html
语料库检索工具的主要功能都差不多,一般人需要的功能就是20个左右而已,WordSmith有一些建库的辅助功能,但是一般人往往没有时间精力和技术知识背景来建库的,例如XML的知识基础。所以,AntConc就是优秀而免费而够用的工具了;WordSmith只是名气大而已,过去的10年里,它和AntConc都开发进展非常迟缓,三五年才更新一次,也更新幅度很小,而世界上的语料工具开发者急缺,所以,外语界只能受制于这样的“有限工具”了。
http://wenku.baidu.com/view/195a3704cc175527072208a3.html
http://www.lexically.net/wordsmith/step_by_step_English6/index.html
WordSmith的众多功能就是两大类:建库功能,用库功能。从宏观到微观可以简明概括如下……
【文件】或【库】统计,对比,拆合,查看,移动,核查,抓取,更名
【词】或【词块】统计,对比,检索,替换
【标注】统计,忽略,剥离
【字符】转换,清理
【最宏观的层次】也就是在对你建库或构成库的众多文件进行统计呀,对比呀,拆分或合并呀,查看阅读呀,移动呀或更名呀,核查完整性呀,抓取大量网页来建库呀。
【最常用的层次】是“词与词块”这个层面的“那些事儿”,量的多角度对比呀,位置的统计或快速确定呀,替换一些字词呀。
【次常用的层次】是“标注”的“纵横使用与计算”;
【最底层或最微观的平面】是字符层面的编码转换了。
AntConc是免费,仅仅缺乏“文件与库”的这个最宏观层面的功能,更微观的更常用的都有了。其实,建库功能也能找其他软件来实现的。
回复: 求助自建语料库步骤
李老师,我正好在纠结需不需要付费购买WordSmith软件,主要用来做文本分析。
比如WordSmith所具备的功能,如生成关键词表,对几个文本的标准类符形符比、平均词长、平均句长的统计,AntConc是否也有类似功能。
我是初学者,所以问题也很初级,因为最近写文章正等着用,请教李老师了,祝暑假愉快!")
李老师,我正好在纠结需不需要付费购买WordSmith软件,主要用来做文本分析。
比如WordSmith所具备的功能,如生成关键词表,对几个文本的标准类符形符比、平均词长、平均句长的统计,AntConc是否也有类似功能。
我是初学者,所以问题也很初级,因为最近写文章正等着用,请教李老师了,祝暑假愉快!
李亮1975重庆
语料库快乐军政委
AntConc的另类技巧与Word VBA的小小编程
平均词长和平均句子可以用Office Word来统计。平均词长是每个词的字母数量,平均句长是每个句子的单词数量或字母数量。你看我的一个视频就知道Word 2003或Word 2007怎么能统计一个txt或doc文件的句子数量从而被你直接或间接计算出平均词长和平均句长了。
http://v.youku.com/v_show/id_XMjQwMDA4NTg0.html?f=5427313
其中的关键代码是……
Sub 句子总量()
MsgBox ActiveDocument.Sentences.Count
End Sub
Sub 单词总量()
MsgBox ActiveDocument.Words.Count
End Sub
Sub 平均句长的单词版()
MsgBox ActiveDocument.Words.Count / ActiveDocument.Sentences.Count
End Sub
你在Microsoft Word中点“字数统计”,就能看到的“字符数(计空格)”和“字符数(不计空格)”的相差的数量就是空格的数量。所以,单词总量除以“字符数(不计空格)”就是平均每个词的字母数量。
AntConc也能间接计算“句子总量”与“陈述句总量”与“疑问句总量”与“感叹句总量”,其虽然不能统计平均词长,但它是免费且能统计单词总量而间接得到每个词含有的平均字母数量;AntConc虽然不能统计平均句长,但它可以检索“. ”,也就是你检索“句号+空格”的数量就几乎逼近句子总量(陈述句的数量)了,在此基础上你为了更加精确就检索“? ”,也就是“问号+空格”,把这个值跟前一个值加起来就得到句子总量(疑问句的数量)了。同时你检索上述两个值的时候,要注意选择主界面上的“Word”这个选项前面的小方框的勾勾,你应该不要勾上它或取消它,这样就把“问号+空格”当作一个字符串来检索,而不是当作一个word而前后自动加上空格来检索了。
平均词长和平均句子可以用Office Word来统计。平均词长是每个词的字母数量,平均句长是每个句子的单词数量或字母数量。你看我的一个视频就知道Word 2003或Word 2007怎么能统计一个txt或doc文件的句子数量从而被你直接或间接计算出平均词长和平均句长了。
http://v.youku.com/v_show/id_XMjQwMDA4NTg0.html?f=5427313
其中的关键代码是……
Sub 句子总量()
MsgBox ActiveDocument.Sentences.Count
End Sub
Sub 单词总量()
MsgBox ActiveDocument.Words.Count
End Sub
Sub 平均句长的单词版()
MsgBox ActiveDocument.Words.Count / ActiveDocument.Sentences.Count
End Sub
你在Microsoft Word中点“字数统计”,就能看到的“字符数(计空格)”和“字符数(不计空格)”的相差的数量就是空格的数量。所以,单词总量除以“字符数(不计空格)”就是平均每个词的字母数量。
AntConc也能间接计算“句子总量”与“陈述句总量”与“疑问句总量”与“感叹句总量”,其虽然不能统计平均词长,但它是免费且能统计单词总量而间接得到每个词含有的平均字母数量;AntConc虽然不能统计平均句长,但它可以检索“. ”,也就是你检索“句号+空格”的数量就几乎逼近句子总量(陈述句的数量)了,在此基础上你为了更加精确就检索“? ”,也就是“问号+空格”,把这个值跟前一个值加起来就得到句子总量(疑问句的数量)了。同时你检索上述两个值的时候,要注意选择主界面上的“Word”这个选项前面的小方框的勾勾,你应该不要勾上它或取消它,这样就把“问号+空格”当作一个字符串来检索,而不是当作一个word而前后自动加上空格来检索了。
附件
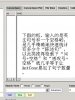
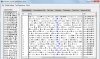
李亮1975重庆
语料库快乐军政委
回复: 求助自建语料库步骤
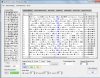
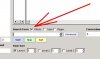
附件中有多个屏幕截图的说明。你的“为什么”的疑问是“怎样才能检索带有标注的汉语却不显示标注”吧,我推测的。
李老师,我用antconc对我已经进行分词后的文本进行检索,但是kwic的检索结果显示的是带有分词标注的文本查询结果,这是为什么呢?我设置也设置成utf-8了,但是还是这样的结果。用你的文本转换器进行分词后的文本转换,转成utf-8,反而还一条结果都差不出来,这是为什么呢??急需你的解答,谢谢啦
附件中有多个屏幕截图的说明。你的“为什么”的疑问是“怎样才能检索带有标注的汉语却不显示标注”吧,我推测的。
附件
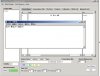
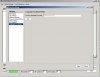
回复: 求助自建语料库步骤
李老师,是这个意思。但是我用你的方法去试了,还是不成功,不知道问题出在哪了。
李老师,是这个意思。但是我用你的方法去试了,还是不成功,不知道问题出在哪了。
附件中有多个屏幕截图的说明。你的“为什么”的疑问是“怎样才能检索带有标注的汉语却不显示标注”吧,我推测的。