You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
用AntConc处理中文concordance, wordlist, N-gram
- 主题发起人 xujiajin
- 时间
清风出袖
高级会员
回复: 为何用AntConc两次检测的结果不一样啊
怎么会不一样?具体说说。
为何用AntConc两次检测的结果不一样啊,好像是每次都不一样,新手上路,请各位大侠指点,谢谢
怎么会不一样?具体说说。
回复: 用AntConc处理中文concordance, wordlist, N-gram
老师,您好,
我用了AntConc,发现有点问题,我用CONCORDANCE,索引"我们",有2007 HITS,但是,我回到COLLOCATE模块后,输入"我"或"们,却只有3个搭配了,按道理,"我"和"们"的搭配也应该有2007个才对呀!也就是说,AntConc不能以汉字找搭配,或者是我的设置有问题?(我完全按本论坛里所说的标准设置的)
请问SMITHWORD有找字搭配的功能吗?难道一定要用它?
麻烦您抽空回答一下.
学生 洪涛敬上
老师,您好,
我用了AntConc,发现有点问题,我用CONCORDANCE,索引"我们",有2007 HITS,但是,我回到COLLOCATE模块后,输入"我"或"们,却只有3个搭配了,按道理,"我"和"们"的搭配也应该有2007个才对呀!也就是说,AntConc不能以汉字找搭配,或者是我的设置有问题?(我完全按本论坛里所说的标准设置的)
请问SMITHWORD有找字搭配的功能吗?难道一定要用它?
麻烦您抽空回答一下.
学生 洪涛敬上
回复: 用AntConc处理中文concordance, wordlist, N-gram
看来你的语料是经过分词了的,这样“我们”就被当成了一个词,情况就出在了并不是语料中的所有“我们”都被分成了“我们”这个词,有3个可能变成了“我”一个词,“们”一个词……
老师,您好,
我用了AntConc,发现有点问题,我用CONCORDANCE,索引"我们",有2007 HITS,但是,我回到COLLOCATE模块后,输入"我"或"们,却只有3个搭配了,按道理,"我"和"们"的搭配也应该有2007个才对呀!也就是说,AntConc不能以汉字找搭配,或者是我的设置有问题?(我完全按本论坛里所说的标准设置的)
请问SMITHWORD有找字搭配的功能吗?难道一定要用它?
麻烦您抽空回答一下.
学生 洪涛敬上
看来你的语料是经过分词了的,这样“我们”就被当成了一个词,情况就出在了并不是语料中的所有“我们”都被分成了“我们”这个词,有3个可能变成了“我”一个词,“们”一个词……
回复: 用AntConc处理中文concordance, wordlist, N-gram
你要检索的是有词性赋码了的语料,光有分词是不行的。
大家好
关于这款软件,我有些地方不是很明白
请大家指点
如何使用这款软件对已经进行了分词的语料进行格式的查询
比如“V+N”这种动词名词组合串?
你要检索的是有词性赋码了的语料,光有分词是不行的。
回复: 用AntConc处理中文concordance, wordlist, N-gram
不懂藏文,不过AntConc还是可以处理的。这里是我的做法:
1、安装himalaya.ttf字体(直接复制粘贴到C:\Windows\Fonts文件夹后系统会自动安装);
2、重新把文本转存成UTF-8的;
3、打开AntConc,设置Global Settings,把Font Settings的三项全部选成Microsoft Himalaya; 把Language Encodings设置成Standard Encodings里的Unicode(utf-8),然后Apply保存设置;
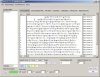
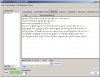
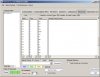
4、导入文本进行分析。这里是截图供参考:
谁能帮我在antconc上试一下这个文本?是藏文的,已经分词了,拜托各位了,我怎么试也显示不出藏文,用的字库是微软vista的himalaya,是unicode编码,字库和文本在附件里,谢谢!
不懂藏文,不过AntConc还是可以处理的。这里是我的做法:
1、安装himalaya.ttf字体(直接复制粘贴到C:\Windows\Fonts文件夹后系统会自动安装);
2、重新把文本转存成UTF-8的;
3、打开AntConc,设置Global Settings,把Font Settings的三项全部选成Microsoft Himalaya; 把Language Encodings设置成Standard Encodings里的Unicode(utf-8),然后Apply保存设置;
4、导入文本进行分析。这里是截图供参考:
附件
回复: 用AntConc处理中文concordance, wordlist, N-gram
谢谢laohong,你真是太棒了!
不懂藏文,不过AntConc还是可以处理的。这里是我的做法:
1、安装himalaya.ttf字体(直接复制粘贴到C:\Windows\Fonts文件夹后系统会自动安装);
2、重新把文本转存成UTF-8的;
3、打开AntConc,设置Global Settings,把Font Settings的三项全部选成Microsoft Himalaya; 把Language Encodings设置成Standard Encodings里的Unicode(utf-8),然后Apply保存设置;
4、导入文本进行分析。这里是截图供参考:
谢谢laohong,你真是太棒了!
回复: 用AntConc处理中文concordance, wordlist, N-gram
许博士,您好:
我刚刚开始涉足语料库,
拜读您在2007年第6期发表的文章,用词匠WS统计的词/语块;
我想问一下,
如何使用Antconc提取语块?
它们二者在提取语块方面,
哪个更方便?
谢谢!
尝试多次,无果而终!
急盼指点!!
谢谢!!!
小和两句。
蚍蜉可堪词匠职,集腋终得成大势。
注:蚍蜉,即蚂蚁,借指Ant(AntConc的中心词)。词匠即是WordSmith。这一句是用来感谢Laurence Anthony的无私之举的。
同时也希望大家通过Corpus4u这个空间,“茹切如搓,如琢如磨
许博士,您好:
我刚刚开始涉足语料库,
拜读您在2007年第6期发表的文章,用词匠WS统计的词/语块;
我想问一下,
如何使用Antconc提取语块?
它们二者在提取语块方面,
哪个更方便?
谢谢!
尝试多次,无果而终!
急盼指点!!
谢谢!!!
回复: 用AntConc处理中文concordance, wordlist, N-gram
AntConc操作更简单,步骤少一些,因为不用建index。但对大语料吃力一点。
http://www.antlab.sci.waseda.ac.jp/software/AntConc_Help/AntConc_Help.htm
N-Grams/Clusters
把Clusters选项卡下的N-Grams勾上就可以了。
AntConc操作更简单,步骤少一些,因为不用建index。但对大语料吃力一点。
http://www.antlab.sci.waseda.ac.jp/software/AntConc_Help/AntConc_Help.htm
N-Grams/Clusters
把Clusters选项卡下的N-Grams勾上就可以了。
回复: 用AntConc处理中文concordance, wordlist, N-gram
Millons of thanks...........
谢谢教导
想不到您的工作效率那么高
现在凌晨2:38
谢谢.......
AntConc操作更简单,步骤少一些,因为不用建index。但对大语料吃力一点。
http://www.antlab.sci.waseda.ac.jp/software/AntConc_Help/AntConc_Help.htm
N-Grams/Clusters
把Clusters选项卡下的N-Grams勾上就可以了。
Millons of thanks...........
谢谢教导
想不到您的工作效率那么高
现在凌晨2:38
谢谢.......
回复: 用AntConc处理中文concordance, wordlist, N-gram
AntConc 对藏文处理是不完善的,他只是可以支持非常多的编码(包括UNICODE编码),本身对藏文一无所知。我刚学了几句藏文,发现如果检索简单藏文字母,AntConc对于有下加字和元音的藏文“字”有错误(说明是字节匹配,不是字匹配)。目前能完美处理藏文检索的只有俺开发的检索系统。可惜,由于某种原因,目前尚不能公开给大家使用,等一段时间吧。不懂藏文,不过AntConc还是可以处理的。
回复: 用AntConc处理中文concordance, wordlist, N-gram
请问
关于concordance中间对不齐,我将所有中文符号改成一般英文的标点,还是不行,请问是否是选择字形的原因。
目前使用法国研发的Unitex打开中文文本做concordance时,也是同样问题,我的老师认为字形(typeface)的关系,要我找可以同时显示拉丁字母及汉字的字形,也就是找字形可以将字母长度及汉字长度视为同一长度。
我爬了文,觉得好像不是字形的关系,请问有人可以帮我解答吗,谢谢
这次在AACL2008(http://corpus.byu.edu/aacl2008/)会议期间,和AntConc的作者Laurence Anthony(http://www.antlab.sci.waseda.ac.jp/)有了“零距离”的接触。和Laurence讨论了一些AntConc的问题,如中文concordance中间对不齐、一次性打开多个文本出错等问题。Laurence解释了问题的原因,也介绍了解决的办法,这里和大家分享一哈:
1、关于中文concordance中间对不齐,他建议最好去除文本中的所有中文标点符号再试试(我还没试);
2、关于一次性打开多个文本导致程序出错,他认为是Windows的系统问题,如果要打开多个文本,他建议使用File, Open Dir...的功能。本人试了一下,确实不错。
另外,Laurence还透露他正在开发自己的ParaConc,预计界面和功能都要比Barlow的好。而且,他还是准备免费推出 -- 各位拭目以待吧。
最后,贴上一张与Laurence的合照,沾名人一点光啊。
请问
关于concordance中间对不齐,我将所有中文符号改成一般英文的标点,还是不行,请问是否是选择字形的原因。
目前使用法国研发的Unitex打开中文文本做concordance时,也是同样问题,我的老师认为字形(typeface)的关系,要我找可以同时显示拉丁字母及汉字的字形,也就是找字形可以将字母长度及汉字长度视为同一长度。
我爬了文,觉得好像不是字形的关系,请问有人可以帮我解答吗,谢谢
回复: 用AntConc处理中文concordance, wordlist, N-gram
藏文如果只做检索Myfind软件也可以,很不错的,只是编码须采用大丁字符集,很方便的。
AntConc 对藏文处理是不完善的,他只是可以支持非常多的编码(包括UNICODE编码),本身对藏文一无所知。我刚学了几句藏文,发现如果检索简单藏文字母,AntConc对于有下加字和元音的藏文“字”有错误(说明是字节匹配,不是字匹配)。目前能完美处理藏文检索的只有俺开发的检索系统。可惜,由于某种原因,目前尚不能公开给大家使用,等一段时间吧。
藏文如果只做检索Myfind软件也可以,很不错的,只是编码须采用大丁字符集,很方便的。
回复: 用AntConc处理中文concordance, wordlist, N-gram
But I am not allowed to download.You can get a copy of AntCon short guide in PDF format at http://www.fleric.org.cn/forum/viewthread.php?tid=216
回复: 用AntConc处理中文concordance, wordlist, N-gram
http://www.antlab.sci.waseda.ac.jp/software/AntConc_Help/AntConc_Help.htm
这里的帮助文件写得很清楚,你可以看一下。
http://www.antlab.sci.waseda.ac.jp/software/AntConc_Help/AntConc_Help.htm
这里的帮助文件写得很清楚,你可以看一下。