You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
BFSU Collocator1.0参数求解
- 主题发起人 wxsong
- 时间
williamJia
开放语料库项目
回复: BFSU Collocator1.0参数求解
f(c) 是共现词在语料库中出现的次数
N 是语料库的总词数
f(n) 是节点词在语料库中出现的次数
f(n,c) 节点词和共现词在语料库中共现的次数
首先非常感谢许博士和William Jia共享这么好的软件!
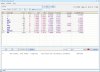
只是在使用过程中对此软件的几个参数不甚了解,麻烦帮我看看!如截图:
f(n,c)想必是和“检索词”的共现频数,其后的几个参数是据此算出的统计值。
请问表格第三列的f(c)、左上角的N、f(n)的值各代表什么?
本以为f(c)是“Collocate”列下的词在语料文本中出现的总频数、N是语料的形符或类符,若是,为何与其在文中出现的实际频数、或形符类符相差甚远?(我用的是生语料)
谢谢!
f(c) 是共现词在语料库中出现的次数
N 是语料库的总词数
f(n) 是节点词在语料库中出现的次数
f(n,c) 节点词和共现词在语料库中共现的次数
回复: BFSU Collocator1.0参数求解
谢谢williamJia!
我用BFSU Collocator1.0处理生语料时得到的f(n,c)值没有问题,但其他几个数值和WST的统计好像很不一样。
譬如:一生语料的
WST 5结果是: tokens=217468 types=10537, 某节点词在文中共出现71次,某共现词出现6次;
Collocator1.0的结果为:N=6163 f(n)=1 f(c)=2;
不知是我哪里操作、理解有误?标注语料目前还没试用过。
f(c) 是共现词在语料库中出现的次数
N 是语料库的总词数
f(n) 是节点词在语料库中出现的次数
f(n,c) 节点词和共现词在语料库中共现的次数
谢谢williamJia!
我用BFSU Collocator1.0处理生语料时得到的f(n,c)值没有问题,但其他几个数值和WST的统计好像很不一样。
譬如:一生语料的
WST 5结果是: tokens=217468 types=10537, 某节点词在文中共出现71次,某共现词出现6次;
Collocator1.0的结果为:N=6163 f(n)=1 f(c)=2;
不知是我哪里操作、理解有误?标注语料目前还没试用过。
回复: BFSU Collocator1.0参数求解
不同工具(WordSmith、AntConc、BNCweb、Co-occurrence、Collocate、Collocator等)得出的MI值、Z值、T值、χ2值、对数似然比值常常有差别。这些差别一种情况是由公式不同引起的,即我们上面提到的以Mike Scott的WordSmith为代表的经典搭配计算法,以及以Stefan Evert提出的BNCweb的搭配计算方法。
在相同计算公式下,如果出现数值差别,可能有如下原因:各软件对形符或单词的定义不一致,比如BFSU Collocator中,我们数字和不同的标点符号视作单独的形符。再有,含有连字符的单词(如255-page)视作一个单词,而不是两个。有些工具中会将所有的阿拉伯数字都归并成一个#。这些都是造成最后的搭配统计值不一致的一些可能因素。
所得的不同搭配强度值,一般来说无对错之虞,只是我们需要弄清产生数值差异的主要原因。
另外,我们应该在同一个课题中坚持用同一种搭配计算工具,并在报告结果时言明。
从搭配信息的结果呈现方式来说,有两种,一种是基于整个语料库中每个词项的所有强搭配的整体呈现。WordSmith和BNCweb都提供这种搭配信息。另一种更常见的基于检索项的搭配信息抽取。包括WordSmith和BNCweb在内的搭配提取工具都可以提供这种搭配获取方式。
不同工具(WordSmith、AntConc、BNCweb、Co-occurrence、Collocate、Collocator等)得出的MI值、Z值、T值、χ2值、对数似然比值常常有差别。这些差别一种情况是由公式不同引起的,即我们上面提到的以Mike Scott的WordSmith为代表的经典搭配计算法,以及以Stefan Evert提出的BNCweb的搭配计算方法。
在相同计算公式下,如果出现数值差别,可能有如下原因:各软件对形符或单词的定义不一致,比如BFSU Collocator中,我们数字和不同的标点符号视作单独的形符。再有,含有连字符的单词(如255-page)视作一个单词,而不是两个。有些工具中会将所有的阿拉伯数字都归并成一个#。这些都是造成最后的搭配统计值不一致的一些可能因素。
所得的不同搭配强度值,一般来说无对错之虞,只是我们需要弄清产生数值差异的主要原因。
另外,我们应该在同一个课题中坚持用同一种搭配计算工具,并在报告结果时言明。
从搭配信息的结果呈现方式来说,有两种,一种是基于整个语料库中每个词项的所有强搭配的整体呈现。WordSmith和BNCweb都提供这种搭配信息。另一种更常见的基于检索项的搭配信息抽取。包括WordSmith和BNCweb在内的搭配提取工具都可以提供这种搭配获取方式。
xusun575
高级会员
回复: BFSU Collocator1.0参数求解
学习中....,但wxsong 提供两种工具(WST和BFSU)得出的某项结果的差距是如此之大(tokens=217468:N=6163),仅形符或词的定义不同可能无法解释。继续学习并存疑...谢谢williamJia!
我用BFSU Collocator1.0处理生语料时得到的f(n,c)值没有问题,但其他几个数值和WST的统计好像很不一样。
譬如:一生语料的
WST 5结果是: tokens=217468 types=10537, 某节点词在文中共出现71次,某共现词出现6次;
Collocator1.0的结果为:N=6163 f(n)=1 f(c)=2;
不知是我哪里操作、理解有误?标注语料目前还没试用过。
williamJia
开放语料库项目
回复: BFSU Collocator1.0参数求解
为了验证那个结果是正确,可以用纯文本工具如ultraEidt打开语料库,查找节点词出现的次数。对比一下就可以出结果,注意查找时要在单词前后都加空格,不然结果不准确(如:banking会计入bank)。也可以用其他语料库工具处理,然后对比一下,我的代码的处理结果和ultraEidt是相同的。
要计算语料库N的大小,可以用ultraEidt打开文本然后统计空格格个数,一般有多少个词就有多少个空格。这样你可以大概得到N的值。
为了验证那个结果是正确,可以用纯文本工具如ultraEidt打开语料库,查找节点词出现的次数。对比一下就可以出结果,注意查找时要在单词前后都加空格,不然结果不准确(如:banking会计入bank)。也可以用其他语料库工具处理,然后对比一下,我的代码的处理结果和ultraEidt是相同的。
要计算语料库N的大小,可以用ultraEidt打开文本然后统计空格格个数,一般有多少个词就有多少个空格。这样你可以大概得到N的值。
williamJia
开放语料库项目
回复: BFSU Collocator1.0参数求解
另外,你可以试一下语料库标注后的统计结果。对于节点词和共现词在语料库中出现的频率可以单独检索一下,作为验证。
另外,colligator 2.0和collocator 1.0只处理tokens不处理types, 所有的数值指的都是token值
如果你要处理types需要,需要自己手动更改检索条件(符合正则表达式),如: go|went|doing|gone
另外,注意设置span的值和最小限制。
我测试了一下生语料没有发现你说的问题。
另外,你可以试一下语料库标注后的统计结果。对于节点词和共现词在语料库中出现的频率可以单独检索一下,作为验证。
另外,colligator 2.0和collocator 1.0只处理tokens不处理types, 所有的数值指的都是token值
如果你要处理types需要,需要自己手动更改检索条件(符合正则表达式),如: go|went|doing|gone
另外,注意设置span的值和最小限制。
我测试了一下生语料没有发现你说的问题。
回复: BFSU Collocator1.0参数求解
不一样。
我们用的是BNCweb公式。
WordSmith和BNCweb各个搭配公式的不同主要不同是BNCweb公式里多考虑到span,而WordSmith所采用的经典搭配公式计算方法,并不都考虑到span。
我们认为搭配是应该考虑span因素的,而不是不受任何限制的词语共现关系,因此,我们采用了BNCweb的公式。
BNCweb Collocations公式请见下面的pdf文件。注意公式中的大S,即span。大家可以比较一下公式中的细微差别。
===========
以下为WordSmith的算法和公式
For computing collocation strength, we can use
· the joint frequency of two words: how often they co-occur, which assumes we have an idea of how far away counts as "neighbours". (If you live in London, does a person in Liverpool count as a neighbour? From the perspective of Tokyo, maybe they do. If not, is a person in Oxford? Heathrow?)
· the frequency word 1 altogether in the corpus
· the frequency of word 2 altogether in the corpus
· the span or horizons we consider for being neighbours
· the total number of running words in our corpus: total tokens
Mutual Information
Log to base 2 of (A divided by (B times C))
where
A = joint frequency divided by total tokens
B = frequency of word 1 divided by total tokens
C = frequency of word 2 divided by total tokens
MI3
Log to base 2 of ((J cubed) times E divided by B)
where
J = joint frequency
F1 = frequency of word 1
F2 = frequency of word 2
E = J + (total tokens-F1) + (total tokens-F2) + (total tokens-F1-F2)
B = (J + (total tokens-F1)) times (J + (total tokens-F2))
Z Score
(J - E) divided by the square root of (E times (1-P)) where
J = joint frequency
S = collocational span
F1 = frequency of word 1
F2 = frequency of word 2
P = F2 divided by (total tokens - F1)
E = P times F1 times S
Log Likelihood
based on Oakes p. 170-2.
2 times (
a Ln a + b Ln b + c Ln c + d Ln d
- (a+b) Ln (a+b)
- (a+c) Ln (a+c)
- (b+d) Ln (b+d)
- (c+d) Ln (c+d)
+ (a+b+c+d) Ln (a+b+c+d)
)
where
a = joint frequency
b = frequency of word 1
c = frequency of word 2
d := frequency of pairs involving neither w1 nor w2
and "Ln" means Natural Logarithm
不一样。
我们用的是BNCweb公式。
WordSmith和BNCweb各个搭配公式的不同主要不同是BNCweb公式里多考虑到span,而WordSmith所采用的经典搭配公式计算方法,并不都考虑到span。
我们认为搭配是应该考虑span因素的,而不是不受任何限制的词语共现关系,因此,我们采用了BNCweb的公式。
BNCweb Collocations公式请见下面的pdf文件。注意公式中的大S,即span。大家可以比较一下公式中的细微差别。
===========
以下为WordSmith的算法和公式
For computing collocation strength, we can use
· the joint frequency of two words: how often they co-occur, which assumes we have an idea of how far away counts as "neighbours". (If you live in London, does a person in Liverpool count as a neighbour? From the perspective of Tokyo, maybe they do. If not, is a person in Oxford? Heathrow?)
· the frequency word 1 altogether in the corpus
· the frequency of word 2 altogether in the corpus
· the span or horizons we consider for being neighbours
· the total number of running words in our corpus: total tokens
Mutual Information
Log to base 2 of (A divided by (B times C))
where
A = joint frequency divided by total tokens
B = frequency of word 1 divided by total tokens
C = frequency of word 2 divided by total tokens
MI3
Log to base 2 of ((J cubed) times E divided by B)
where
J = joint frequency
F1 = frequency of word 1
F2 = frequency of word 2
E = J + (total tokens-F1) + (total tokens-F2) + (total tokens-F1-F2)
B = (J + (total tokens-F1)) times (J + (total tokens-F2))
Z Score
(J - E) divided by the square root of (E times (1-P)) where
J = joint frequency
S = collocational span
F1 = frequency of word 1
F2 = frequency of word 2
P = F2 divided by (total tokens - F1)
E = P times F1 times S
Log Likelihood
based on Oakes p. 170-2.
2 times (
a Ln a + b Ln b + c Ln c + d Ln d
- (a+b) Ln (a+b)
- (a+c) Ln (a+c)
- (b+d) Ln (b+d)
- (c+d) Ln (c+d)
+ (a+b+c+d) Ln (a+b+c+d)
)
where
a = joint frequency
b = frequency of word 1
c = frequency of word 2
d := frequency of pairs involving neither w1 nor w2
and "Ln" means Natural Logarithm
附件
回复: BFSU Collocator1.0参数求解
各位前辈好!
[FONT=宋体]有关[/FONT]BFSU Collocator 1.0 的数值想请教一下各位!
[FONT=宋体]我只需要此工具提供MI[FONT=宋体]和[/FONT]Z[FONT=宋体]值,来判断显著搭配词。所得结果,[/FONT]Log-log[FONT=宋体],[/FONT]Log-likelihood[FONT=宋体]有些值为[/FONT]0[FONT=宋体],但[/FONT]MI[FONT=宋体],[/FONT]Z[FONT=宋体]值达到显著搭配词的判断标准,那这些词还能被视为显著搭配词吗?[/FONT]Log-log[FONT=宋体],[/FONT]Log-likelihood [FONT=宋体]这两个数值具体有什么用途?能麻烦各位解释一下吗?我没找到有关清楚解释,不清楚这两个数值在语料库中什么意义。[/FONT][/FONT]
[FONT=宋体][FONT=宋体][FONT=宋体] 希望各位百忙之中能解答一下我的问题!非常感谢啊!!![/FONT][/FONT]
[/FONT]
各位前辈好!
[FONT=宋体]有关[/FONT]BFSU Collocator 1.0 的数值想请教一下各位!
[FONT=宋体]我只需要此工具提供MI[FONT=宋体]和[/FONT]Z[FONT=宋体]值,来判断显著搭配词。所得结果,[/FONT]Log-log[FONT=宋体],[/FONT]Log-likelihood[FONT=宋体]有些值为[/FONT]0[FONT=宋体],但[/FONT]MI[FONT=宋体],[/FONT]Z[FONT=宋体]值达到显著搭配词的判断标准,那这些词还能被视为显著搭配词吗?[/FONT]Log-log[FONT=宋体],[/FONT]Log-likelihood [FONT=宋体]这两个数值具体有什么用途?能麻烦各位解释一下吗?我没找到有关清楚解释,不清楚这两个数值在语料库中什么意义。[/FONT][/FONT]
[FONT=宋体][FONT=宋体][FONT=宋体] 希望各位百忙之中能解答一下我的问题!非常感谢啊!!![/FONT][/FONT]
[/FONT]
各位前辈好!
本人在做一类词的显著搭配词,请问BFSU Collocator 1.0 中的MI,MI3,Z值,T值,Log-log值和Log-likelihood值分别在哪个范围内为显著搭配,有没有约定俗成的临界值?
本人在做一类词的显著搭配词,请问BFSU Collocator 1.0 中的MI,MI3,Z值,T值,Log-log值和Log-likelihood值分别在哪个范围内为显著搭配,有没有约定俗成的临界值?
Last edited: